Published: Dec 6, 2019 by Ivana Žemberi
What’s your first thought when you hear the term Data Structures? Mine was that it’s something like a struct in C++, a collection of different types of data that you can use in your programme.
I was not entirely wrong, as its name suggests, the struct truly is a kind of a data structure. But there is much more to know about Data Structures to fully understand them.
Now, I have written a simple programme where I use structure to collect data about a student and print it out.
 |
 |
If I’d wanted, I could expand my programme. Firstly I could enable multiple entries, then I could create new functions, perhaps I could calculate the average grade for each subject. Or for each student. Or even both. For that, I would also use the same data collected in tdata (the t in front of the name stands for the data type).
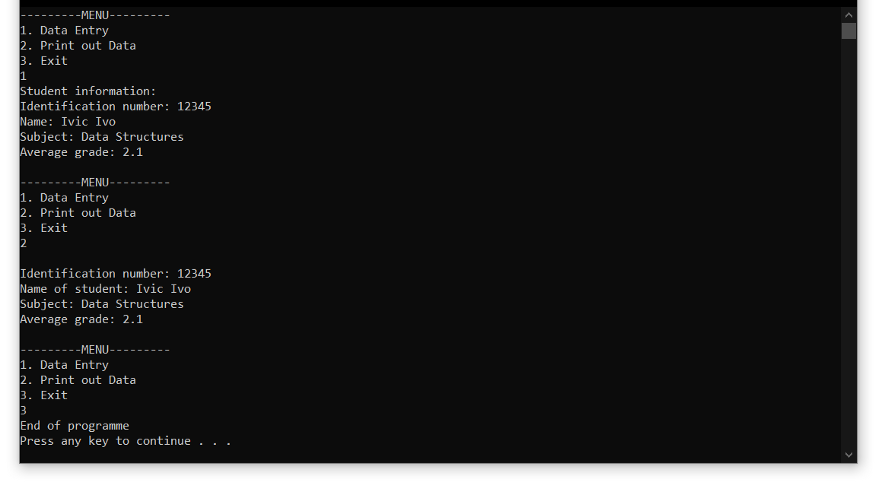
For this use, this Primitive Data Structure type is more than enough. Before I continue, let’s see how many types of data structures we can distinguish:
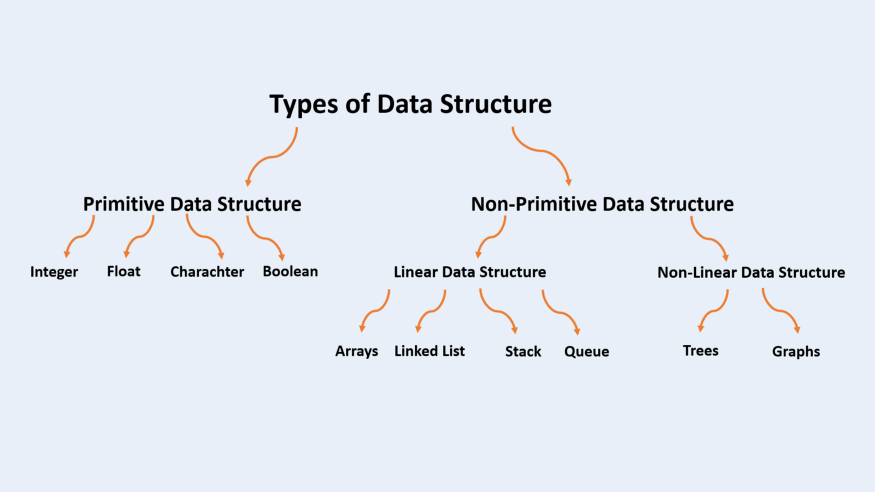
So, when speaking of Data Structures, people usually drive at this other kind — The Non-Primitive Data Structure. Although it is more complicated than the Primitive one, it is also much more useful.
After all, the principal idea of Data Structures is to store and manage data.
It makes sense that the data with more implemented functions will be easier to manage. That’s why we have so many different implementations for different types of data.
I won’t get into the Non-linear Data Structures because I am not very familiar with them, but I will try to clarify the differences between the Linear ones.
So, as I said earlier, it’s easier to manage your data when you have the right implementation for it. I will try to explain more further this whole meaning of implementations by example:
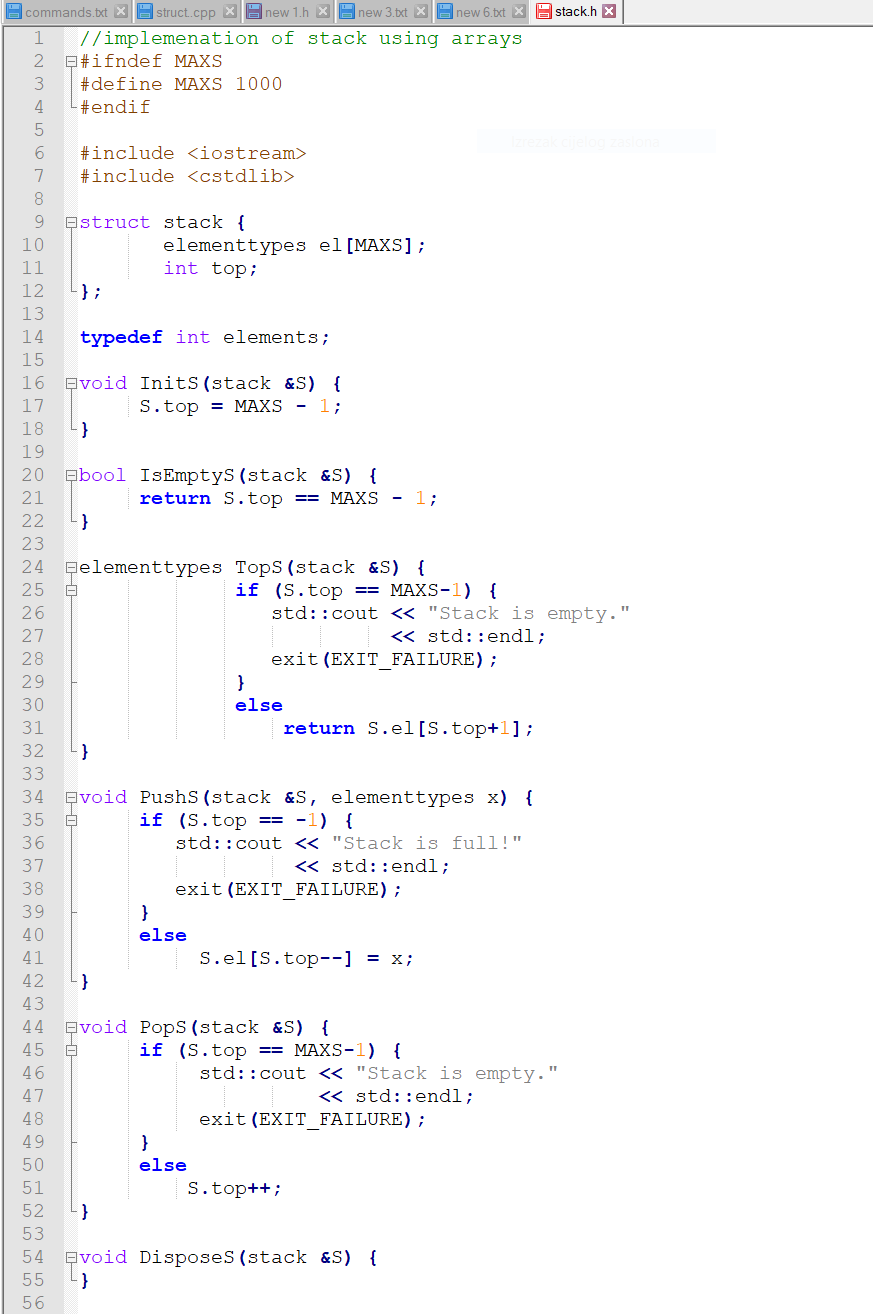
This code above shows an implementation of stack using arrays. We could also make this implementation by using pointers, but it will be easier to explain some basic concepts on the array one.
Implementations are saved as .h type file (header files). We use them by including them in the .cpp files. Then in the .cpp file, we write the main code where we use functions from the .h file.
Every Abstract Type Data (ATD) has a defined type of data that presents an element or a knot in itself.
Naming rule: element + the first letter of the ATD to which it refers.
Our ATD is Stack so our element is called elements.
Values that are stored in a single element are of a general type of data. Naming rule (similar as above):
elementtype + the first letter of the ATD to which it refers.
Our stack will be built over the elementtypes data type. Elementtypes needs to be defined in the declarative part
of the programme, before including the header file. That will be shown later in the .cpp file.
The beginning of header file usually consists of including iostream and cstdlib libraries. What is important is that you cannot use the command using namespace. By using that command, implementation is unusable for programmes that redefine their namespaces.
Also, you need to define the maximum value that the element can store.
Then you can make a structure that consists of elementtypes el[MAXS] and integer top that shows what is on the top of the stack.
After struct, you define elements and stack using the command typedef.
Now functions, every function has its use and the first one is initialization.
void InitS(stack &S) sets the cursor on MAXS-1.
bool IsEmptyS(stack &S) checks the value of cursor S.top, if its value equals MAXS-1 it returns true, otherwise false.
void PushS(stack &S, elementtypes x) checks if the value of cursor S.top equals -1. If it is, then it writes that the stack is too full. Otherwise, it adds an element on the stack and moves the cursor for one place above.
elementtypes TopS(stack &S) checks if the value of the cursor equals MAXS-1. If it is then it writes the stack is empty, otherwise, it returns the value from the top of the stack.
void PopS(stack &S) also checks the value of the cursor. If it equals MAXS-1 it writes that the stack is empty. Otherwise, it moves S.top for one place down.
And in the last function is:
void DisposeS(stack &S), that function doesn’t do anything. But it is needed for deallocation of elements when using pointers instead of arrays.
Here below is an example of a programme with the implementation from above:
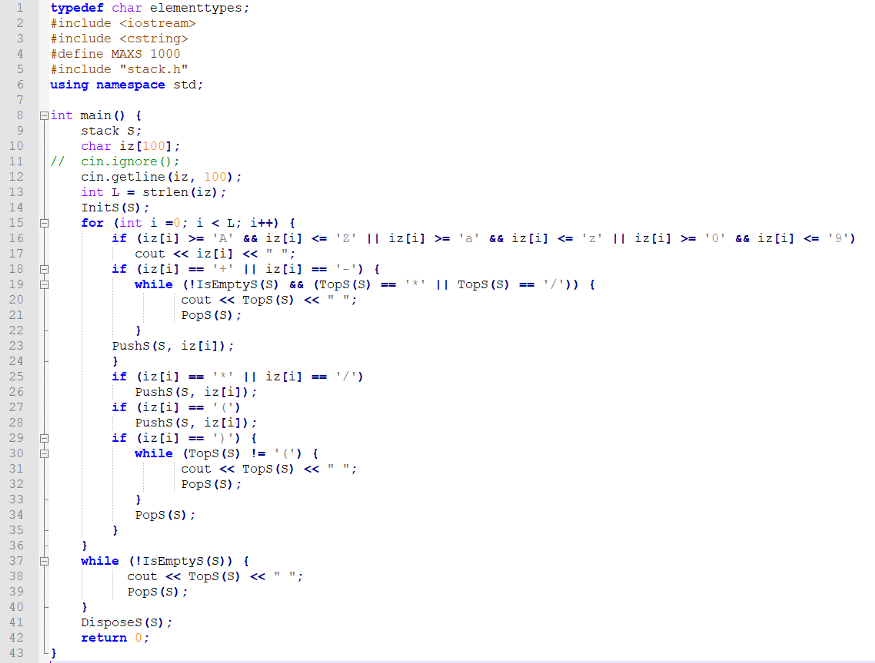
What does this programme do? It changes the infix notation to postfix notation. Postfix notation doesn’t use brackets. This programme uses the stack implementation for storing the brackets and the values and operators by priority.
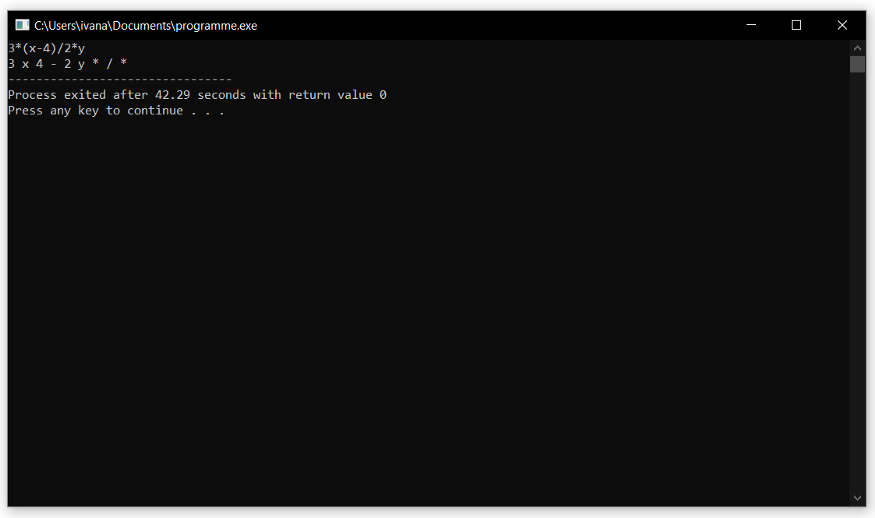
Here we see an example of infix notation changes to postfix notation.
Conclusion
Data Structures are complex and it takes a lot of time to understand them. You work with the abstract type of data, and it can be very confusing sometimes, especially if you’re studying a few other classes at the same time.
However, programmes without data don’t do much. Without the data, you don’t really have anything to program.
That’s why Data Structures are important to understand even if they make you struggle a bit.

